MongoDB - Geo Index 에 대한 연구
1.연구배경 및 요약
MONDO DB는 사용자의 현재 위치를 활용해 근방의 위치정보데이터를 가져오는 방식으로 Geo index뿐 아니라 일반 인덱스도 사용할 수 있다.
이 실험은 정말로 Geo index가 근방의 위치데이터 탐색에 더 빠른 TPS를 보여 주는가 에 대한 궁금증으로 시작하였다.
본 연구에서는 여러 상황을 설정한 후 각 상황에 적합한 index를 선정하고 그 이유에 대하여 분석하여 설명한다.
2.MongoDB의 Geo-index.
MongoDB에서는 총 3가지 Geo-index를 제공한다.
2d index , 2d sphere index, Geohaystack index이다.
2-1. 2d index
MongoDB의 2d-index는 Geohash함수를 기반으로 사용한 index이다.
Geo hash는 위치데이터를 가져올 때 일단 지구를 셀로 나눈 후 해당 위치가 어느 나라,어느 행정지역에 있는지 분석한다.
분석하면 같은 위치에 있는 데이터는 밑의 사진과 같이 접두사가 같다.

2-2. 2d sphere index
MongoDB의 2d sphere-index는 Google의 S2 Geometry 라이브러리(C++)를 사용한다.
S2 Geometry라이브러리 역시 위치데이터를 가져올 때 일단 지구를 셀로 나눈 후 해당 위치가 어느 나라,어느 행정지역에 있는지 분석한다.
(단,S2 Geometry 라이브러리는 다음 그림과 같이 3차원 데이터를 나타낼 수 있다.)
역시 각 영역에는 공통된 접두사(Face ID)가 존재하고 이 Face ID를 먼저 읽어야 더 세부적인 위치데이터 탐색이 가능하다.

2-3. Geo haystack index
Geo haystack index는 따로 Geo 기반의 함수나 라이브러리를 사용하지 않았다.
이 인덱스는 MongoDB에서 따로 만든 index로서 bucket이라는 집계함수를 사용하여 만든 인덱스이다.
3.실험 환경
CPU: AMD 7 2700x Eight-Core Processor
Memory: 16GB
SSD:128GB
OS: Ubuntu 16.04.6 LTS
WebServer: Nginx 1.10.3
Database: MongoDB 4.2.5
4.저장한 데이터 구성
시나리오에서 사용될 데이터 구성으로 두 시나리오 모두 공통적으로 적용된다.
4.첫 번째 시나리오.
시나리오: 일정 거리 안의 미용실 데이터를 거리 계산하지 않고 가져온다.
해당 실험은 MongoDB에서 지원하는 Find 함수를 사용하여 위치데이터를 검색하였다.
50000개의 문서에서 사용자의 현재 위치를 기반으로 근처에 있는 “미용실”데이터를 가져오는 상황이다.
매번 랜덤한 위치에서 1km 5km10km 반경으로 미용실 데이터를 20개까지 검색한다.
1분 동안 1초에 100명의 사용자가 꾸준히 접속한다고 가정한다.
첫 번째 시나리오에서 진행하는 50000개의 문서는 좁은 지역에 밀집된 데이터이다.
5.첫 번째 시나리오 밴치마크
테스트 결과 1km 내에서는 2d-index와 2d-sphere index가 빠르지만 탐색범위가 커질수록 점점 속도가 느려지는 것을 확인 할 수 있었다.

테스트 결과 1km 내에서는 2d-index와 2d-sphere index가 빠르지만, 탐색범위가 커질수록 점점 속도가 느려지는 것을 확인할 수 있었다.
6.첫 번째 시나리오 벤치마크 결과 분석.
결과를 분석하기 위해 내가 실행한 Find 함수가 어떻게 사용되는지 분석하였다.
일단 MongoDB는 위치데이터를 분석할 때 Geo Server를 사용한다.
GeoServer란?
지리공간 데이터를 공유하고 편집할 수 있는 오픈 소스 GIS 소프트웨어 서버이다.
MongoDB에서는 Geo Server에서 제공하는 서비스 중 MWS라는 Web Map Service를 활용한다.
MWS란 서버에서 생성하는 이미지를 인터넷을 통해 제공하는 표준 인터페이스로서
서버상(World Wide Web)에서 GIS가 제공하는 지도를 사용한다.
Analytical web maps이라는 기능을 제공하는데 이 기능을 통해 인터넷상에서 좌표를 가지고 분석할 수 있게 해준다.
이 서비스를 사용하기 위해서는 WGS84 같은 국제 표준형식을 사용해야 한다.
Find 함수의 아키텍처를 분석해 보면 Geo Server를 사용하기 위하여 WGS84 형식을 사용한다.

2d index와 2d sphere index에는 Geo 라이브러리가 포함되어 있다.
사용자 위치데이터를 가지고 근방의 위치데이터 탐색 시 Geo라이브러리 규칙에 따라 변환한 후 그 데이터를 가지고 분석 후 근처 데이터값을 가지고 온다.
2d index와 2d sphere index를 사용한 Find 함수의 흐름은 이러하다.
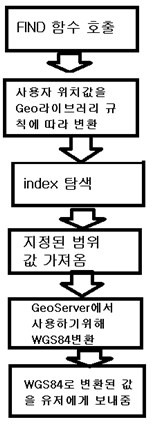
데이터를 찾을 때 Geo 라이브러리를 사용하여 위치데이터를 변환한 후 근처의 위치데이터를 찾기 때문에 일정 가까운 영역의 위치데이터를 검색할 때는 속도가 빠르다.
이유는 2d index와 2d sphere index가 근처에 있는 데이터는 같은 접두사를 가지고 있기 때문에 같은 접두사를 가진 데이터를 가지고 오면 되기 때문이다.
반면 넓은 위치에 있는 데이터는 데이터의 접두사가 같지 않기 때문에 Geo 라이브러리를 사용하면 오히려 느려진다.
6.두 번째 시나리오
시나리오: 일정 거리 안의 미용실 데이터를 거리 계산하고 가까운 순서대로 가져온다.

사용자의 현재 위치를 기반으로 주변위치를 탐색하여 근처 위치에 있는 미용실 데이터를 찾는 상황이다.
해당 실험은 MongoDB에서 지원하는 집계함수를 사용하여 사용자의 현재 위치 기반으로 근처에 있는 미용실의 거리까지 측정해주는 함수로 Geo index만 사용할 수 있다.
200,000개의 문서에서 사용자의 현재 위치를 기반으로 근처에 있는 “미용실”데이터를 가져오는 상황입니다.
매번 랜덤한 위치에서 1km 5km10km
반경으로 미용실 데이터를 20개까지 검색한다.
1분 동안 1초에 100명의 사용자가 꾸준히
접속한다고 가정한다.
두 번째 시나리오에서 진행하는 200,000개의 문서는 첫 번째 시나리오보다 데이터 위치가 고르게 분포되어 있다.
7.두 번째 시나리오 밴치마크 결과 및 분석
처음으로 한 테스트의 결과이다.
이때 Geohaystack index의 TPS가 다른 Geo index보다 확연히 낮았다.

이러한 결과 값이 나온 이유를 조사하기 위해 아키텍처를 분석하였다.

geohaystack에서 사용하는 집계함수의 아키텍처다. 보는 바와 같이 문서를 하나하나 검색할 때
scale을 최대 거리 / bucket size로 계산하여 문서 값을 하나하나 검색한다
즉, 최대거리가 클수록 bucket size가 작을수록 TPS는 느려진다.
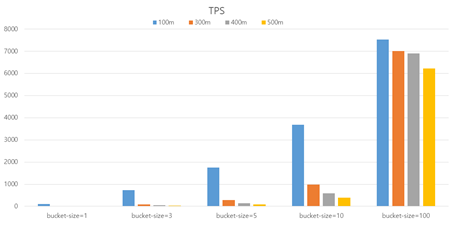
그에 따른 테스트 결과이다.
실제로 테스트해본 결과 bucket size를 증가시킬수록 TPS가 빨라지는 것을 확인할 수 있다.
최종적으로 bucket size를 조정한 후 거리를 10,000m를 추가해서 한 번 더 테스트를 해 보았다.
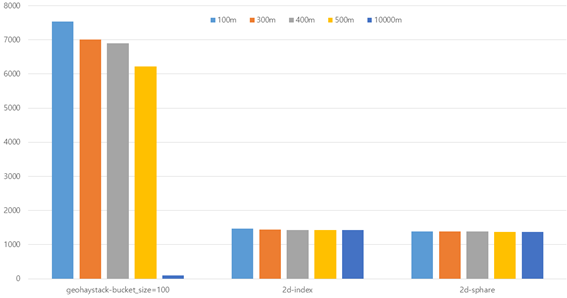
bucket size가 커지면 확실히 속도가 빨라지지만 넓은 영역에서 데이터를 가져올 경우에는 TPS가 느려진다.
반면 2d-index와 2d sphere-index는 넓이에 따른 차이가 별로 없었다.
최종결과 분석
2d-index와 2d sphere-index에서 사용되는 집계함수 geoNear의 경우 모든 문서를 가져와서 하나하나 거리를 계산하는 방식이 아닌 문서를 가져와서 확인 후 지정된 범위 내에 있는 데이터면 문서를 배열에 넣고 다시 다음 문서를 확인한다.
이렇게 문서를 하나하나 확인 한 후문서 20개를 다 찾으면 사용자에게 결과 값을 보내주는 방식이다.
Geohaystack-index에서 사용하는 집계함수 geosearch의 경우 index로 데이터에 접근할 때 사용된다.(2d-index와 2d sphere index는 접근해서 데이터를 가져온 후 집계함수를 사용한다.)
index를 만들 때 버킷을 설정하여 위치데이터를 bucket 안에 저장한다.
그 후 찾을 때는 그 bucket 안에 있는 문서를 하나하나 전부 찾아가며 사용자 현재 위치에서 가까운 20개의 데이터를 찾는다.
즉,2d-index와 2d sphere-index는 엄청나게 넓은 거리에서도 일정한 속도를 유지 할 수 있지만 정확하게 사용자에게서 가까운 거리순으로 데이터를 가져올 수는 없다.
또한 요청하는 데이터가 많으면 느릴 수 있다.(나는 영역 안의 미용실 데이터 20개를 가져오는 테스트였지만 요청하는 데이터 개수가 늘어나면 느려질 수 있다.)
때문에 넓은 범위에서 요청개수가 많지 않고 명확한 상황에 사용하기를 추천한다.
8.연구 결론
위치기반의 서비스를 사용한다고 해서 무조건 Geo index를 사용하는 것을 추천하지 않는다.
현 서비스 상황에 따라 Geo index가 좋을 수 있고 오히려 안 좋을 수도 있다.
또한 직접 index를 만드는 것이 더 효율적일 수 있다.
고정관념을 깨고 현재 서비스 상황에 맞춰 적절한 index를 선택하는 것이 좋겠다.
9.참고자료
https://docs.mongodb.com/manual/tutorial
https://github.com/mongodb/mongo/blob/master/src/mongo/db